-
���}�|�l���㷨ģ��푑��C��̽��
2024/4/3 11:38:12����Դ:�Ї��a�I�lչ�о��W�������w���� �� С�����ղر��������ӡ�����P�]��
������ʾ���S�����ּ��g���w�ٰlչ������ИI�đ��ÝB�������ڲ���a���ͅR�ۡ������ѳɞ���ИI�lչ�Ļ��A��Ҫ�غ͑������YԴ���S�����ּ��g���w�ٰlչ������ИI�đ��ÝB�������ڲ���a���ͅR�ۡ������ѳɞ���ИI�lչ�Ļ��A��Ҫ�غ͑������YԴ���Ԇ��}�錧��“�Ô����fԒ���Ô����Q�ߣ��Ô����������Ô�������”�ѳɞ���ИI���ֻ��D�ͺ��|���lչ����Ҫץ�֡�ᘌ����}�ķ�������Ҳ���ɽ���Д��������D׃��“�����x��”���ڽ������и��I���ɴˣ��Ĕ��������}����ͨ�^��������������}��Q���ߣ���ɞ锵���x�ܵ���Ҫ��ʽ���ڴ˷�ʽ�£��˂�������ᘌ��������}�Ĕ����ɼ�������̎���ͷ�������ҕ���O�y��څ���Д���A���A�y�ȹ��̼��g����Aע������Ͷ�룬�����چ��}�ı�ԭ���������}�a���ĸ�Դ�����ݡ�߉�����|��e�Լ���β����R�e���្��푑��ȷ�������ȱ�������Pע���༴���ڔ����x�ܑ����^���У�ȱ�������}���F�����}�R�e�����}�្�͆��}푑��ȘI�խh�����ĝB�c����Ͷ�䣬�Ķ������Ԇ��}�錧��Ĕ����x���������I�խh������“�ݶ���ʧ”��
�Ԇ��}�錧��Ĕ����x�ܑ�؞���Ć��}���F�����}��Q��ȫ�^�̣��������}���F�����}�R�e�����}�្�͆��}푑�(����푑����}���_����Q���������m��Q����)���h�����༴���ڔ����x�ܑ����^���У����Ć��}���F�����}�R�e�����}�្�͆��}푑���ȫ朗l�Ƕȣ��Ԇ��}��������ϣ����㷨ģ�͞��������棬���F���������ڸ��h���ĝB�cͶ�䣬���������x���ڸ��h����“�ݶ���ʧ”���@���У��㷨ģ�ͼ���푑��C�������P�I��
��ˣ�������������Փ(Grounded Theory)����ԭ�l���}�្�U�l������W�о�������������}�|�l���㷨ģ��푑��C�Ƙ���˼·��ּ��ͨ�^�㷨ģ�͵Ę��������ú͵����������Ć��}���F�����}�R�e�����}�្�͆��}푑���ȫ�^�̔��ǻ���푑��C�ơ�
һ�����w˼·
������֪���������d����Ϣ����Ϣ�N����֪�R��֪�R�����x���ǻۑ����Ԅ���rֵ���S�����ּ��g���w�ٰlչ���ڸ��и��I�����둪�ã���������}��ͨ�^���ֻ����g�M�Д��ֻ�ӛ䛣��γɆ��}���������@Щ���}�����M���ռ�(�γɆ��}��)��̎���ͷ������ھ����е���Ϣ��֪�R���醖�}���С����}푑��͆��}��Q�ṩ�Q���������@�������Ԇ��}�錧��Ĕ����x�ܵĻ���߉��
���H�^���У����ֻͣ���ڔ����ɼ�������̎���ͷ�������ҕ���O�y��څ���Д���A���A�y�ȹ��̼��g����(��Ҋ���D1)�����چ��}�ı�ԭ���熖�}�a���ĸ�Դ�����ݡ�߉�����|��e�Լ���β����R�e���្��푑��ȷ���ȱ�����Ŀ��]������“�����I�ջ�”�����漰����֡�
���D1 �Ĕ����ɼ����A�y�A����ʾ��D

���}�|�l���㷨ģ��푑��C�ƌ������ڏ�ԭ�l���}�ı�ԭ̽�����l���Ć��}���F�����}�R�e�����}�្�͆��}푑��ȸ��h�����֣��Ԇ��}��������ϣ����㷨ģ�͞��������棬�����Ć��}���F�����}�R�e�����}�្�͆��}푑���ȫ�^�̔��ǻ���푑��C��(��Ҋ���D2)�����F“�����x��”؞���Ć��}���F�����}��Q��ȫ�^�̡�
���D2 ���}�|�l���㷨ģ��푑��C�ƿ��w˼·
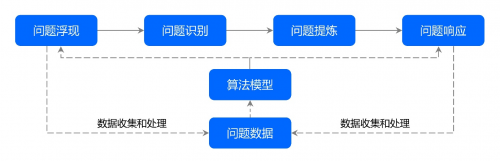
�ĸ��D2��Ҋ�����}���F�������C�Ƶ����c�����}푑��������C�ƵĽK�c�����߶��dž��}�����ā�Դ——ǰ���dž��}�ij�ʼ��Դ�������dž��}��Q��Ч�ķ��������Ҙ�����һ�����}�ĸ��F����Q���]�h��ͨ�^�����}���F�͆��}푑��Ĕ����ռ���̎�����γɆ��}�����죬���γ��ˆ��}�|�l���㷨ģ��푑��C�Ƙ���֮Դ���@Ҳ�dž��}“�I�Ք�����”�^�̡����}�R�e�͆��}�្�dž��}“�����I�ջ�”�ĺ��ģ��ǏĆ��}���F�����}푑����ǻ��D�Q�������ǻ�֮Դ�������㷨ģ�͡��㷨ģ�ͷ��b�˶�N���A�㷨��ᘌ����ֱ���á��ض��΄ս�Q�������������棬�@Щ�㷨������ͨ�^�����}�����ķ������ھ�Ч���ʵ��R�e���}�ā�Դ�����������ݡ�e���������P����(��o���¼���ͻ�l���顢���c����������y�cʹ�c���c�¼��ȵ�)�����������}�R�e�ĽY����������Щ���ό��H�Ŀ��|�����ɿ��ơ��ɽ�Q�Ć��}��ͬ�r�្�����}�е����P��������}���Y�Ϛvʷ���(���ߎ�)��һЩ�˗U�������M���្�������Ć��}��Q��Փ�wϵ��푑����ߣ��Ķ����F“�����x��”؞���Ć��}���F�����}��Q��ȫ�^�̡�
�������}���F
���}���F�������C���γɵ����c��Ҳ�dz�ʼ���}�����ռ��ā�Դ���o�ɣ��˽↖�}���F�������c���������P�I��
��Փ�ǹ��������I��߀���̘I�I���}���F����������������ȵĸ���V����Ͷ�V����P�����h����ԃ�������c�u�r�ȵȣ�Ҳ�Ё��Ե��������{����o�ȵķ��ձO���^���е����Ӱl�F�����}���F������Ҳ�漰��Դ��
�Թ������՞��������}�ĸ��F�Ё�����I��Ⱥ�������ӷ�������ͨ�^12345���՟ᾀ����ͨ�^���շ��պò��uƽ�_������ͨ�^�������մ�d���O����(��“���k��”����)��Ҳ�Ё����ڴ��{�л�������{���^���е����Ӱl�F����ͨ�^�Y�������Y���������İl���c���}�ɼ���߀�Ё����������T�����c�¼��Pע��̷��^���еİl�F��������“�p�S�Cһ���_”�̷��O���^���е����Ӱl�F��Ҳ���������P���W�k��ƽ�_�c�������Wý�w�ıO�y�^���еĆ��}���@�ȵȡ����}�ă��ݿ����漰�������棬�����շ��ա��I�̭h�����Ј��O�ܡ����B�h��������������������ȫ���������ռ����������}�Ľ��c�����漰һЩ�L���ԁ����y�c�����c��ʹ�c��Ҳ�����漰һЩͻ�l�����l����c�¼����ֻ��漰�������TijЩ���c�Pע���¼��ȵȡ�
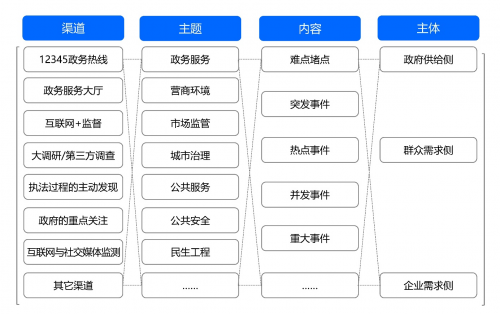
��ͬ�������ăH�Ǐĸ��I��ϵ�y�ռ�������ԇ�D�Ĕ������ھ��}�������}���F�������˽��c�����������ڶ�������ǶȲ��@���}�ĸ��F���e�nj��ڝ��ڵ��[�Ԇ��}�İl�F��Ҳ��������չ���}�������ռ�����(����{�С��������{�顢�LՄ�����h�f�̡��z�yӛ䛵ȵ�)�����������ռ����|����ͬ�r�������}���F�������˽⌢���������}���F�C����ȫ�����պ������˽⣬����m�Ć��}�R�e�����}�្�͆��}푑��������×l�������ϣ����}���F�����������}�����ݺ����w֮�g�ľ�ꇈD�V�͘����˾��Ć��}���F�ęC���������總�D3��ʾ��
���D3 ���}�����������}�����ݺ����w֮�g�ľ�ꇈD�V
�������}�R�e
���}�R�e�����ھ��}���������R�e���}����͡��@������������Փ�|���о������팍�F�����Ȍ����}�����M��Ԕ���ķ�͘˺���̎�����R�e���}�Ļ������������(���Q“��ʼ���a”)��Ȼ���@Щ����������M���P����������֮�g��߉ϵ���l���Pϵ������C�ƣ��ҳ����������}����(���Q“���S���a”)�����_��һ���������}�����@�@�����}�������}��������������}�ĺ��ĽY��(���Q“�x���Ծ��a”)�����^�������a�����ھ��}���������R�e���}����͡�
�Թ��������I���еĠI�̭h�����}��������ǰ���������I�̭h�����}���Զ�Դ���Ё������Ք����YԴ�죬Ҳ�Ё�������I�LՄ���I��С�MӑՓ�����P�ļ��Y�ϵ�����������߀�Ё�����12345���՟ᾀ�����պò��u��Ͷ�Y�������ġ������^���е��^��ӛ䛣��Լ��������շ��I��ϵ�y�ȡ����ڌ��I�̭h�����}���F�C���������M�ж�Դ�����ռ���̎�����γɠI�̭h�����}�����죬�Դ����醖�}�R�e���|���о����ϡ�
���ȣ����Ҳ���ӛ���I�̭h�����}�����й����p���P�ڠI�̭h�������̓����ij�ʼ�����c�������ݡ����磬����I����ȿ��ܕ��l�F��“ϣ�����ӹ�ƽ���Ј��h��”“˾��������s”“�Ŀ؛����Ƿ����”“�й��y”�ȱ����c�I�̭h���������P���V������c�������ݡ������߹��o�ȿ��ܕ��l�F��“�P���Mһ���ӏ������YԴ���ױO�ܵ�ָ����Ҋ”“֪�R�a�ౣ�o”“���ñO��”“�˲���Ӗ�c�˲����M����”�ȱ����c�I�̭h���������P�ij�ʼ�����c�������ݡ�
Ȼ���@Щ��ʼ��������������M�з���P�����w�����្��һ���������}�����С��猢“ϣ�����ӹ�ƽ���Ј��h��”��“�P���Mһ���ӏ������YԴ���ױO�ܵ�ָ����Ҋ”�w����“�Ј��h��”�@�����}��“˾��������s”��“֪�R�a�ౣ�o”�w����“���ƭh��”��“�Ŀ؛����Ƿ����”��“���ñO��”�w����“���íh��”��“�й��y”��“�˲���Ӗ�c�˲����M����”�w����“Ҫ�حh��”�ȵȡ�
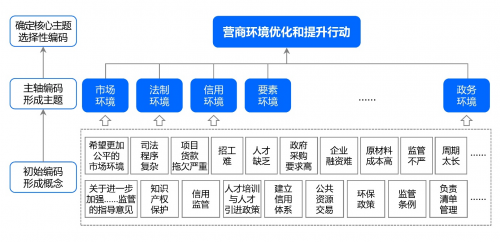
��_��һ���������}�����ϸ������}���������_��“�I�̭h�������������Є�”�@���������}����“�Ј��h��”“���ƭh��”“���íh��”“Ҫ�حh��”���������}�������M�����ϣ��γ�ᘌ��I�̭h�������������ЄӵĻ�����Փ��ܡ���Ҋ���D4��
���D4 ᘌ��I�̭h�����}�ľ��a�c�R�e-1
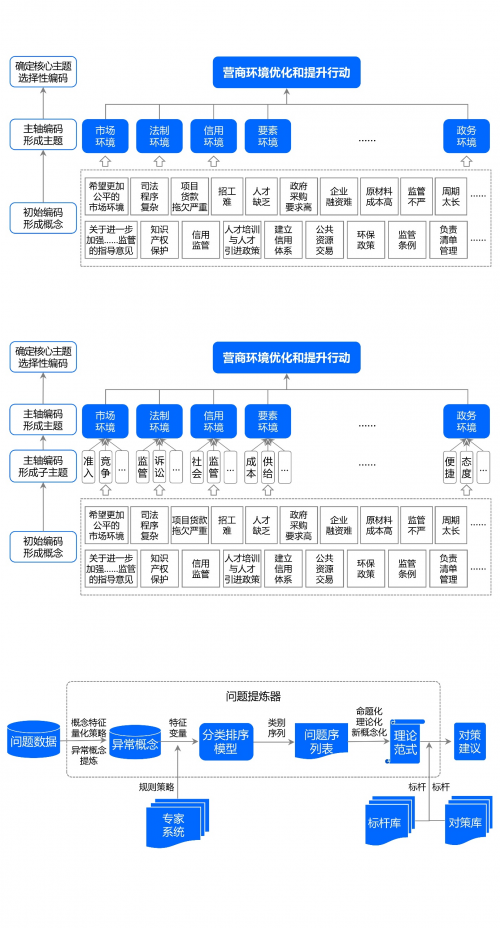
���H�^���У��ɸ�����Ҫ�Mһ�������}�������֞�༉�����}���������磬��“�Ј��h��”�Mһ�����֞�“�Ј�����”“�Ј��O��”�ȣ���“���ƭh��”���֞�“�����O��”“�����V�A”��“���íh��”���֞�“�������”“���ñO��”�ȵȡ���Ҋ���D5��
���D5 ᘌ��I�̭h�����}�ľ��a�c�R�e-2
���]���c�O�y���u�rָ�˵�������һ�£��چ��}�R�e�^���У��ɽ������P�O�y�c�u�r��ָ������ƥ�侎�a�^���е����P��������}������ᘌ��I�̭h�����}���Ʌ��ՠI�̭h���u�rָ���wϵ���M�С�
�ġ����}�្
�چ��}�R�e�γɸ�������}������Փ��ܵĻ��A�ϣ��Mһ�����@Щ�����M���P��ƥ�䣬���F���}�្������һ���Ć��}푑��ṩ���h�c��Փָ�������}�្��Ҫ�漰��������ĺ��ă��ݣ��្�����еĮ�����r(�γ���Ʒ���㷨�е�ؓ��������);����������r�Ŀ��|���ԡ��ɿ��ԺͿɲ����ԣ����Y����������׃����������γɆ��}����(�ஔ�ڌ�ؓ���������M�еȼ��������);�Mһ�������}�M������ھ��γ��µĸ�������}���������}�µ���Փ��ʽ�����Y�Ͻ��ߺ�һЩ�˗U�������Ɇ��}푑��Č����c���h(�ஔ�ڌ�ؓ�������M�з����ھ���γɵČ����c���h)���ļ��g�Ƕȶ��ԣ��@�������ă��ݘ�����“���}�្��”��������Ĺ��ܡ���Ҋ���D6��
���D6 ���}�្����������Ĺ���
���ԠI�̭h�����}��������I�ȵ�����������ȵĹ��o�ǠI�̭h�����}�ăɂ����档������چ��}�R�e�Ļ��A�ϣ��Ɍ������M�й���֮�g���P��ƥ�䣬�l�F����֮�g��Щ�������һ���ԣ���Щ������ڲ��ֲ����Щ��������@���_ͻ��ì��(�����³��F�ĸ�����g�Ͽ�ҕ����)�ȡ�����I����ȵ�“ϣ�����ӹ�ƽ���Ј��h��”�c�������o�ȵ�“�P���Mһ���ӏ������YԴ���ױO�ܵ�ָ����Ҋ”֮�g������һ�µģ�“˾��������s”�c“֪�R�a�ౣ�o”֮�g���ܴ��ڲ��ֲ����“�Ŀ؛����Ƿ����”�c“���ñO��”��“�й��y”�c“�˲���Ӗ�c�˲����M����”֮�g���ܴ����@���_ͻ��ì�ܡ���Ҋ���D7��
���D7 �I�̭h�����}�еĮ��������្ʾ��D
���У�һ�����f���I�̭h���������Є��ǝM������ģ����ڲ��ֲ���f���I�̭h������Ҫ�Mһ�����ƺ̓����������ڛ_ͻ��ì�ܵĻ��³��F�ĸ���t��Ҫ���c�Pע��
�b�ڲ������еĮ���������к����ԺͿɽ��ԣ�������}�្�ĵڶ������ă��݄t���Mһ���������}�Ŀ��|���ԡ��ɿ��ԺͿɲ����ԣ��������p�ؾ����c�������P����׃��(���̶ȡ��o���̶ȡ�ͻ�l/���l/���c�����Ӱ푡������ԡ��ɽ��ԡ��y�׳̶ȵȵ�)��ͨ�^�������ģ�����Ɇ��}���С��@���ֹ�����Ҫ�������PҎ�t�͌���ϵ�y���M�С�
���}�្�ĵ��������ă������Mһ�������}�M������ھ��γ��µĸ�������}���������}�µ���Փ��ʽ�����Y�Ͻ��ߺ�һЩ�˗U�������Ɇ��}푑��Č����c���h�����w���ԣ�ͨ�^�Mһ������ʼ���}�M������ھij�ʼ���}�ı������្������w���Pϵ�����ԡ��¼����������P�IҪ�ؼ���֮�g��߉�Pϵ������C�ƺ�֪�R�D�V������ϵ���µ����}������ͬ�r��ͨ�^�����ھ����ʼ���}���P�I߉��Ҏ�t���Mһ�����្���C�Ϻ����ϲ�ͬ������ͬ���γ�ϵ���µĸ�����������Y��ǰ���Į��������͆��}���У������µĺ������}���µĸ���������µ����}���µĺ������}�M���γ��˳�ʼ���}���µ���Փ��ʽ���ڴ˻��A�ϣ��ٽY�Ͻ��ߺ�һЩ�˗U�������Ɇ��}푑��Č����c���h��
�塢���}푑�
�چ��}푑��h���������چ��}�្���ɵČ����c���h��ᘌ��Ե��ƶ������Ľ�Q�������醖�}��Q�ṩ�Є�ָ�ϡ�
���ƶ���Q����֮ǰ��������Ҫ�������}�្�A���្�������P���}Ҫ�أ��熖�}�ă��ݡ����|�͆��}���w�ȵȣ��Q���Ƿ���Ҫ�Mһ���c���}���w(���}�����˻��������P��)�M�М�ͨ�����ھ��}���挍ԭ�⡣���ձ��^�Ƿ�����I�����c�Pע���ش��¼�֮�С�ͬ�r��������ͬ�Ć��}���ݡ����|�����w���ھ��}�ĺ���Ŀ����ʲô����ҪͶ����Щ�YԴ�͗l������Ҫ��Щ���ɷ�Ҏ֧�κͱ��ϴ�ʩ����Ҫ������Щ�Q�߳��������ڕ��ж��L�����к��Ƿ���_�����}�ĺ���Ŀ�ˡ����@Щ�Q��׃���M����һ���M�����ݺ�ģ�M�����A��Ч�����_�����}�ĺ���Ŀ�˕r������γɽ�Q�������Є�ָ�ϡ������_�����A��Ч���Ć��}������һ�r�Ҳ����õČ��ߵĆ��}�����Խ��b�����ط��Ć��}��Q�˗U���_���Լ��Ľ�Q������
��֮���چ��}푑��h����������Ҫ���چ��}�្�Č����c���h���_�����}��Q��Ҫ��Ҫ�ؗl�����γɆ��}��Q�ĕr�g·���D��Ȼ��ͨ�^�M�ϲ�ͬ�ėl��׃���M�����ݺ�ģ�M���γ���ᘌ��ԵĆ��}��Q�������@�㘋���ˆ��}푑��͆��}��Q�Ļ������ܺ���Ҫ߉��
�����]�h�����چ��}푑��͆��}��Q�ij�Ч��Ҫ�Mһ����ۙ���γɆ��}푑��͆��}��Q��“��ۙ��”�����ڳ�Ч���ߵĽ�Q��������Ҫ�Mһ���������P�l��׃���͕r�g·���D�������_�����}����Ŀ�˵Ľ�Q����������γɾ��Ѕ����rֵ��“���ߎ�”�����պ��؏͆��}�Ľ�Q�ṩ�Ԅ�푑��C�ơ���Ҋ���D8��
���D8 ���}푑��^��ʾ��D
�����P�I���g
���}�|�l���㷨ģ��푑��C�ƣ���Ȼ�x���_�����ռ�������̎���͔���������һЩ���ô����g��֧�֣����������������˜�Ҏ���͔�����ȫ�ȷ���ļ��g���á���ǰ�Ŀ�֪���㷨ģ�͞��������棬�nj��F�����x��؞���Ć��}���F�����}�R�e�����}�្�͆��}푑�ȫ�^�̵��P�I����ˣ���������ӑՓ�㷨ģ�͘������P�I���g��
ͨ��������������Փ���о����Խ�����һЩ�����ܛ�����߁팍�F����Nvivo��MAXQDA��QDA Miner�ȡ��M���@Щܛ���ھ��a������F���^�������ܣ�Ȼ����Ч�����Ԍ���“����ʽ”���ƣ��ڜʴ_��������������˹����A���e����“��Փ�”�h����Ҫ�؏��ռ��ͷ���������ȱ���Ԅӻ������ܻ���
��������C���W����������ȌW�����g�õ����L��İlչ���e���S��ChatGPT�ij��F����GPTs�����������ʽ�˹��������ڑ��õ����и��I�С�����ӑՓ���㷨ģ���P�I���g��ȫ����ÙC���W���㷨�팍�F����Ҋ���D9��
���D9 �C���W���㷨�چ��}�ӵ��㷨ģ��푑��C���еđ���
�چ��}���F�h��������ͨ�^“���ܽ���”�������Z���R�e���g�������D���R�e���D��ָ�͈D���Ĵ�ģ�ͼ��g�팍�F�����}���F�IJ��@�c���}�������ɡ�
�چ��}�R�e�h�������ԽM���\�÷��~���g(��N-gramģ�͡��[Markov ģ�͡������ģ�ͺ��W�j�㷨)��TF-IDF���ı������x���c������ģ�ͼ��g�x���}�����е���������;�\���~�������g(��Word2Vec)�͝��ڵ������ֲ�(LDA)���}�������g������ȡ���}�����е��P�I�~���������}�����ɘ�ʾ���}�c�P�I�~֮�g�ę�����r���������}�c�P�I�~֮�g���Pϵ���R�e�P�I�~֮�g���Z�x�Pϵ�����ƶ�;ͨ�^֪�R���V���g(�猍�w��ȡ�����w���R����Ԫ�M��ȡ���¼���ȡ�ȼ��g)���ھ���N����֮�g���P�Pϵ���������ı�����ı���ȼ��g���醖�}�R�e�ṩ���S���ļ��g�ֶΡ�
�چ��}�្�h����ͨ�^�����w���R��Ĺ�����Ԫ�M����ֵ�M�б��^���������R�e����֮�gͬһ�����ȵĸ����Ƿ�һ�£����Ƿ���ڲ���������@���_ͻ��ì�ܵ���r�����ڮ�������ɸ������}�Ŀ��|���ԡ��ɿ��ԺͿɲ����Լ������������P����׃��(���̶ȡ��o���̶ȡ�ͻ�l/���l/���c�����Ӱ푡������ԡ��ɽ��ԡ��y�׳̶ȵ�)��ͨ�^�������ģ�����Ɇ��}���С���ͨ�^�����ɷַ���(PCA)���ؓ��ꇷֽ�(NMF)���g�Mһ����ȡ���}���������������}���γ��µĸ�������}�����γɆ��}������Փ��ʽ���Y�Ϛvʷ���͘˗U���������ChatGPT����ģ�����Ɇ��}푑��Ľ��h�͌��ߡ����w�ϣ��������g���ЙC�M���γ���һ�����}�្����
�چ��}푑��h������ͨ�^�vʷ����Ӗ��һЩ��ֱ�I���ģ�ͣ��������}��Q�����еėl��׃�����r�g·���D�c���}��Q��Ч֮�g�Č����Pϵ�����Դ˴�ģ�������Q�����İ��ݺ�ģ�M�����������}��Q�����ƶ��ĿƌW�ԡ�������Embeddingsģ�͡�RAG�z���������ɺ����������켼�g�ȣ����醖�}푑��ṩ���܆�����ęnժҪ�����������������}푑��^���е��Ԅӻ������ܻ���
���H�^���У��@Щ�㷨ģ�͵ļ��Ϙ����ˆ��}�ӵ��㷨ģ��푑��C�Ƶ� “�㷨��”������؞���Ć��}���F�����}�R�e�����}�្�͆��}푑�ȫ�^�̵�“�����И�”����Ҋ���D10��
���D10 �Ć��}���F�����}푑��������И�——�㷨��
�ɴ˿�Ҋ�����}�|�l���㷨ģ��푑��C�ƣ�����������Փ���о�������˼·����ԭ�l���}���|���о����ϣ����㷨��������ИУ��Ķ����F�Ć��}���F�����}�R�e�����}�្�͆��}푑�ȫ�^�̵��Ԅӻ������ܻ����鹫�����պ��̘I�����I���������F�Ԇ��}�錧��l�]�����Ļ��AҪ�غ͑����YԴ�����ṩ��һ�N�µ�˼·̽����
���`�^���У����c��Ҫ������������Ĺ�������һ�dž��}�wϵ������ģ�͜ʂ䡣ᘌ�ijһ�ИI���I�Գ���ԭ�l���}�錧�����冖�}���F��Դ�^���ռ��vʷ���}��Դ������ͨ�^��ֱ�ИI��ģ��Ӗ�����������w���}���F�O�y�����}�R�e�����}�្�͆��}푑��������㷨ģ��(��)�����������}�˜ʻ��wϵ(ָ�ˎ�)����12345���՟ᾀ�������������}���F��Դ�^��Ҫ��12345�Ԓ���롢�������������c����������շ���ƽ�_�ĝM����u�r�ͺò��u�����{�С��������{�顢����Wý�w�������ȡ�ͨ�^���@Щ�����Ěvʷ�����M���ռ�������12345���՟ᾀ�ИI��ģ�ͣ����������w12345�ᾀ����}���F�O�y�����}�R�e�����}�្�͆��}푑��������㷨ģ��(��)(��ģ������APIs)��������12345�ᾀ���}�˜ʻ��wϵ(����}ָ�ˎ�)�͌��ߎ졣�ڶ��dž��}�្���Ę������������㷨��Ę����^���У������ʼ���}�µ���Փ��ʽ��������Ҫ���棬���}�្���������㷨ģ��푑��C�����������P��Ҫ�����á����}�្�������������ܛQ�����¸���������}�្���|����Ҳ�Q�����µ���Փ��ʽ�����M�ԣ��Ķ�Ҳ�Q���ˌ����c���h�ĿƌW�Ժ͜ʴ_�ԡ�����ᘌ����w���ֈ������}�đ��á������������Ć��}�˜ʻ��wϵ�����ߎ���㷨ģ��(��)���O�y���w���ֈ������}�ĸ��F��ͨ�^���}�R�e�����}�្(���}����)�͆��}푑�(���ݺ�ģ�M)�����������w�Ľ�Q���������}��Q�����ij�Ч������ۙӛ�(��ۙ��)�������]�h���������������㷨ģ�͵đ���������(���ߣ����c�Д��S��܊��Ԭ ��)
�����������İ���wԭ�������У��D�d���H�����������Ϣ֮Ŀ�ģ������֙��О飬Ո��һ�r�gϵ�҂��Ļ�h�����]�䣺cidr@chinaidr.com�� -
- ���c�YӍ
- 24С�r
- ������
- ������
- ���꽛����������I�_���R���sӆ�Ρ�æ���a �R����ɫ�aƷ���N�������p����
- ʮ��y�� �������A �|ܛ�s��һ���t�조�¸��С���ê���
- ���F·�Ρ����m���� ��ظ�ԭ���^���������Ό����_��
- ���I�Ώġ�С���w�~�����M�� �����I+���á���Ԫ����ጷ��½������L�c
- ��ش�W���Oδ��W������ �ߵȽ�����δ��ʽ���Lɶ��
- �I��ʮһ�d���ڱ��T���� ���� �۬��s 2026 C-NPS 늄�����܇Ʒ� TOP1
- �����³��Ј� ����Λρվ����{�� �ܲٳ��2026Λρվ�\�I��ɳ�����Ͼ�����
- ���������˖|�����W���������v�P���W��2026���A���W�I���A�M��Ļ
- �����Ϳ����С���꣺�ԡ��_�w�ߴa�A5Ԫ�ف�һƿ�����ӭ�´�
- �\�Юa�ܾS�ָ�λ �����X�q���ܷ����m


��� | �Wվ��B | �P���҂� | �aƷ�c���� | �̘I���� | ����� | �������� | �̘I�YӍ | ϵ�҂� | ����朽� | �Wվ�؈D
���������������б����д��·ʮһ̖11̖�̄�4�ӡ��]����100141
�����\�I���ģ������н������g�_�l�^�P�Ƕ�·10̖��ؕr���V��C��12��
ȫ�����M��ԃ�ᾀ��400-680-5790 (7*24С�r�������ԃ�Ԓ��18411010258 ���棺010-58850975
�I����ԃ������17810330644�������� ����]����cidr#chinaidr.com(��#�Q��@) ����QQ��330291710
Copyright © 2009-2025 chinaidr.com, All Rights Reserved���a�I�lչ�о��W ������� �Wվ�䰸����ICP��11011445̖-2
���������������б����д��·ʮһ̖11̖�̄�4�ӡ��]����100141
�����\�I���ģ������н������g�_�l�^�P�Ƕ�·10̖��ؕr���V��C��12��
ȫ�����M��ԃ�ᾀ��400-680-5790 (7*24С�r�������ԃ�Ԓ��18411010258 ���棺010-58850975
�I����ԃ������17810330644�������� ����]����cidr#chinaidr.com(��#�Q��@) ����QQ��330291710
Copyright © 2009-2025 chinaidr.com, All Rights Reserved���a�I�lչ�о��W ������� �Wվ�䰸����ICP��11011445̖-2